This guide is to provide information on text mining and analysis such as types and tools, project examples, useful websites, etc. You are welcome to contact us if you would like to get advice or information in doing your research.
The Library welcomes CUHK faculty members and researchers to collaborate with us in conducting digital scholarship research. Please visit our Digital Scholarship Projects page for the projects conducted.
Contact us
Email: dslab@lib.cuhk.edu.hk
Tel.: (852) 3943 9954
Located on the G/F of the University Library, The Chinese University of Hong Kong, the Digital Scholarship Lab aims at providing a cutting-edge space for supporting digital scholarship research.
Contact us
Email: dslab@lib.cuhk.edu.hk
Tel.: (852) 3943 9954
(Source: Elsevier. (2015). What is Text Mining?, https://www.youtube.com/watch?v=I3cjbB38Z4A)
Text mining can be broadly defined as a knowledge-intensive process in which a user interacts with a document collection over time by using a suite of analysis tools. In a manner analogous to data mining, text mining seeks to extract useful information from data sources through the identification and exploration of interesting patterns. In the case of text mining, however, the data sources are document collections, and interesting patterns are found not among formalized database records but in the unstructured textual data in the documents in these collections. (Feldman and Sanger, 2007:1)
Five Major Phases of Text Mining
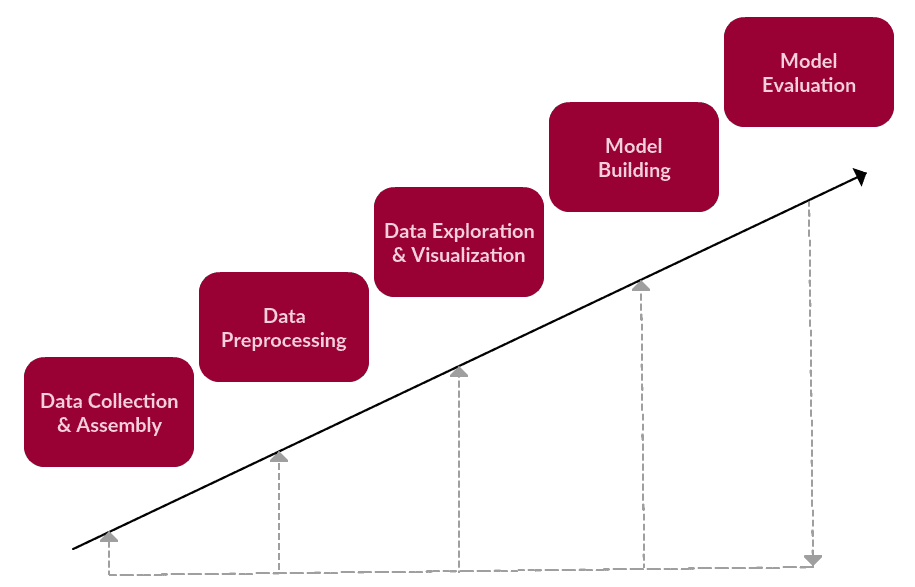
(Source: KDnuggets. A General Approach to Preprocessing Text Data, https://www.kdnuggets.com/2017/12/general-approach-preprocessing-text-data.html)



